

#12. Measuring Experiment Health
monitor your experiment before you make a product decision

Hello experimentation friends.
The content of this week’s post is about simple metrics that can ensure your test is running smoothly. Having metrics to easily monitor your experiment will reduce the effort needed to understand if your experiment ran correctly if you’re analyzing why your test results were not what you expected.
Unrelated, I’ve received a few messages asking when I’ll publish my evaluation of croissants. This is happening soon! Very soon. More croissants need to be consumed for a proper analysis first.
Thank you for reading.
We run experiments to evaluate the effect of a change on users before that change may be in the hands of all of your users. Before a product decision can be made, results and data analysis are conducted to understand the effect.
However, how do you know your test results are valid?
You know you’ve been there.
You look at your metrics after a test has run through its pre-defined duration and something looks off. Your first thought is usually – was this experiment correctly configured?
The only thing worse than not using A/B testing to evaluate product changes—maybe—is running an experiment for months or weeks and realizing something went wrong that prevents users insights to be gained.
What follows are a handful of metrics you should keep in mind to measure your experiment health, while your experiment is running.
Experiment Health Check Metrics
When you go to the doctor's office, they do various tests to get a sense of your general state. Your blood pressure is often checked alongside your weight, height, and temperature. One could refer to these tests as a general health check, emphasis on general. If a specific test were trending in the wrong direction it would lend itself to doing more tests.

Similarly, backend services have health check metrics to monitor the performance of the service in production. For example, availability – is the service up and running? Or response time – is the service meeting expectations with regards to its response time to clients?
We have health check metrics for our personal health and the health of our backend services, so, why not have health check metrics for experiments that ultimately inform product decisions? Experiment health check metrics aim to reduce the effort needed to understand if your experiment ran correctly and was therefore, healthy!
Experiment Health Check #1: Total Allocated Users Metric
In a classic, simple experiment configuration, you have two variants, also called treatments – test and control. The experimentation platform assigns users to the control and test variants, given some criteria usually defined before your test starts. How do you know enough users were allocated to your experiment? Or, even once users are assigned to an experiment, are they receiving the right treatments?
To answer these questions, compute the number of unique users allocated to both the test and control variants. This number may not grow over time if your allocation logic suggests users should be assigned the first week of an experiment. The bucketing logic directly effects how this graph would be illustrated.
Experiment Health Check #2: Impressions Per Variant Metric
Now that you know users were assigned correctly to the test and control variants, the next metric you’ll want to have available when monitoring your experiment (or understanding if your experiment ran correctly after the fact) is whether users were exposed to the feature as expected. Exposures can be measured by impression events.
You’d be surprised how handy having a query to understand whether a user *saw* what you expected them to see comes when verifying if your experiment was correct.

Experiment Health Check #3: User Distribution Metrics
Good experiment platforms can make it easy, or somewhat easy, to identify user distributions, given a user attribute that matters to the product. For example, you may want different tenure users (new vs. existing users) or users from various regions. Before you analyze your test results, check whether your experiment has a distribution of different types of users or key off your test results to see if there’s a difference in the effectiveness of specific user groups.
Experiment Health Check #4: Engineering System Metrics
Latency matters. If your product is slow, you run the risk of your users becoming frustrated and even having a bad brand. We’re all users of products, we can probably easily identify a product that is somewhat slow. This is why latency and your engineering system metrics matter.
To combat risking launching a change that could degrade the load time of your product or feature, make sure you have a graph or some understanding if your test variant is serving the experience in a similar timely fashion to the control variant. If the user experience is slower than the control, that could easily influence your success metrics.
Caching also matters. What if your cache hits increase, and you're returning stale or outdated results? This could affect your user engagement metrics as well.
These are just two examples but there are plenty of engineering system metrics that are worth considering when monitoring your experiment.
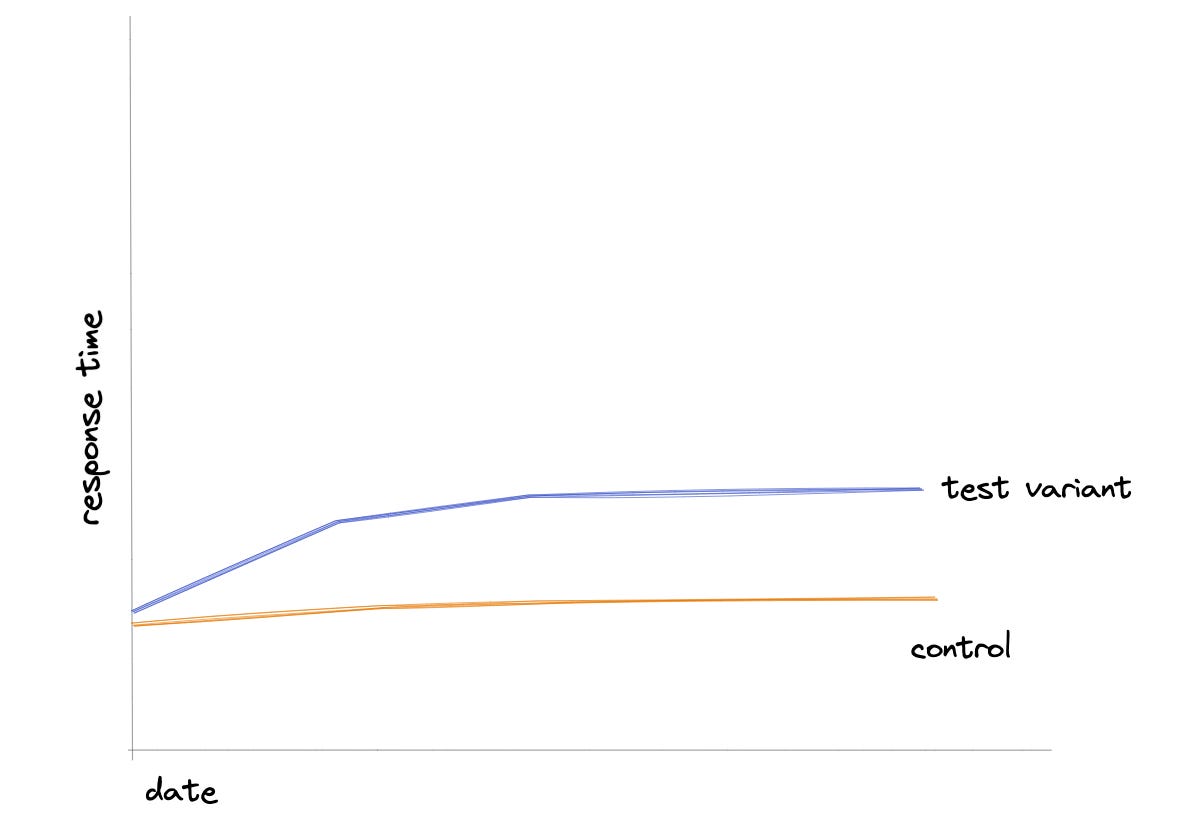
Experiment Health Check #4: Daily Success Metrics
In case there are gaps or days missing that could skew results, it's convenient if you can view your metrics not just in aggregate but also a daily view. The intent isn’t to examine the metric but rather ensure there isn’t a day that’s missing.
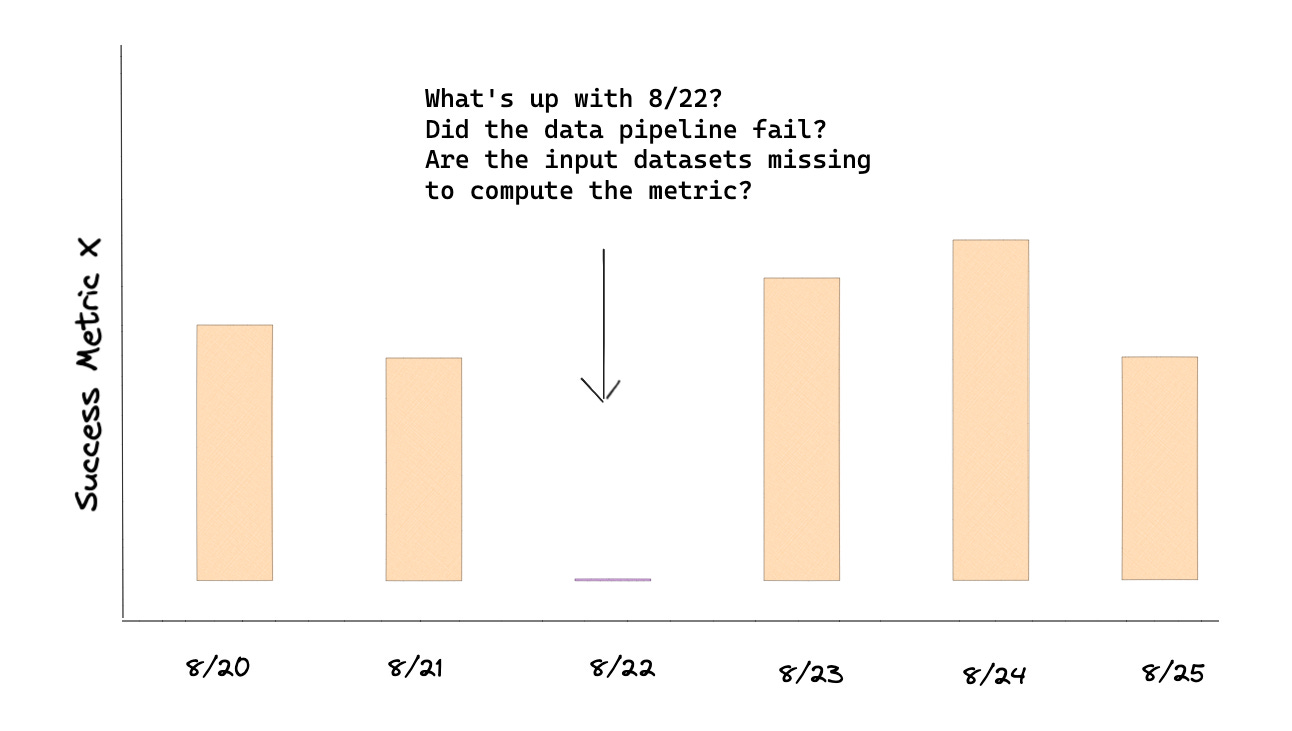
This is a general list, but there are definitely more experiment metrics that you could monitor, given your specific use case and product.
Remember, the goal of monitoring the quality of your experiment is to reduce the effort needed to understand if your experiment ran correctly if you find that you’re questioning your test results.
Or perhaps, make it a best practice to monitor your experiment so you can catch experiment issues earlier rather than later to end the test early vs. realizing weeks later. Suppose you’re at a company where experimentation is seen as an extra step instead of a necessary step. In that case, it’s best to be proactive with your monitoring. Or even if you’re working at a company obsessed with the experimentation methodology, you don’t want to lose time running an experiment that won’t lend itself to product insights because the experiment itself is defective.

That’s all for this Monday! Thanks, as always, for being here, friends. Special thank you to those that bought Practical A/B Testing. If you have comments or suggestions to any of the above subjects, respond to this email.
Happy Experimenting!