


Welcome back to Experimenting, a bi-weekly newsletter where I share stories about A/B testing software, croissants and everything in between.
For the second post, the premise of this story is simple: what do you do when you’ve put so much time into an experiment and then find out the effect wasn’t what you thought it would be? This will be the last reference to the For You A/B test on a video product for a few months as I have a lot of other fun experimentation concepts and stories in the queue.
I hope you enjoy it. Thank you for reading!

FADE IN:
Let’s set the stage.
You get the results of an experiment in which all bets were hedged.
The results are unbelievable.
Not unbelievable in a good way, unbelievable in a bad way.
In the…”wow…maybe we were wrong”-way.
Or in the…“we have zero product intuition”-way.

After the initial shock sets in, you question the experiment’s validity.
Maybe it's the data…because it can always be a data problem. Or perhaps the test itself was configure incorrectly. Or maybe there was an unforeseen seasonality effect.
ENTER DATA SCIENTIST; TRUSTY, BELOVED, AND VERY TENURED
This is the scene where your favorite data scientist says: “A/B testing tells you what happened, but it doesn’t tell you why it happened.”
To understand why your results suggests such an effect, you have to dig into the data. You have to deconstruct the user segments and analyze the data at more granular levels.
Once you do this, your unbelievable results may be more…believable.
FADE OUT.

Return Of The For You A/B Test
Let's revisit the For You A/B Test on the video product that was introduced in the first post.
On this video product, we tested the effectiveness of a personalized For You homepage. The control variant was editorially driven, with some personalization sprinkled between the promotional content. The test variant was the reverse — recommendations driven with some editorial content sprinkled between the personalized content. The objective was to measure the impact of the personalized experience compared to the editorial experience.
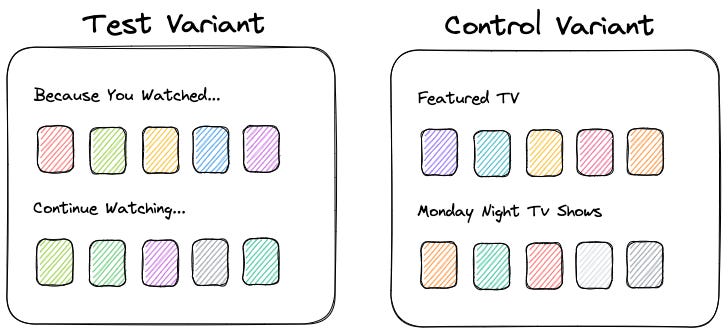
When we were building the For You homepage, we really believed in it. It didn’t even cross our minds that this wouldn’t be super successful — big, huge, massive metric gains were over the horizon! There was no way the test variant wouldn’t outperform the control.
Side note: This was when I learned it's best never to get attached to an idea. It’s OK to get attached to having an impact and improving the experience for your users but do not get attached to a particular idea—more on this in a future post.
The Test Results Were…Not Great. Not Great At All.
The initial test results were embarrassing, unbelievable really. There was a very slight increase in the success metric for users that received the For You homepage, emphasizing the word “slight.”
How could a personalized and dynamic For You homepage result in just a slightly higher metric gain compared to the editorial experience?
It just didn’t make sense.
We expected mammoth-sized gains, not just a slight increase.
When It Doesn’t Make Sense, Make It Make Sense
We listened to our trusty data scientists and conducted comprehensive data analysis. With each query, we slowly started to understand what was happening.
First, we deconstructed the user segments by ensuring there were no discrepancies in the overall segment composition. The users that composed the control and test segments were similar in demographics and tenure. Which is good; we wouldn’t want differences here.
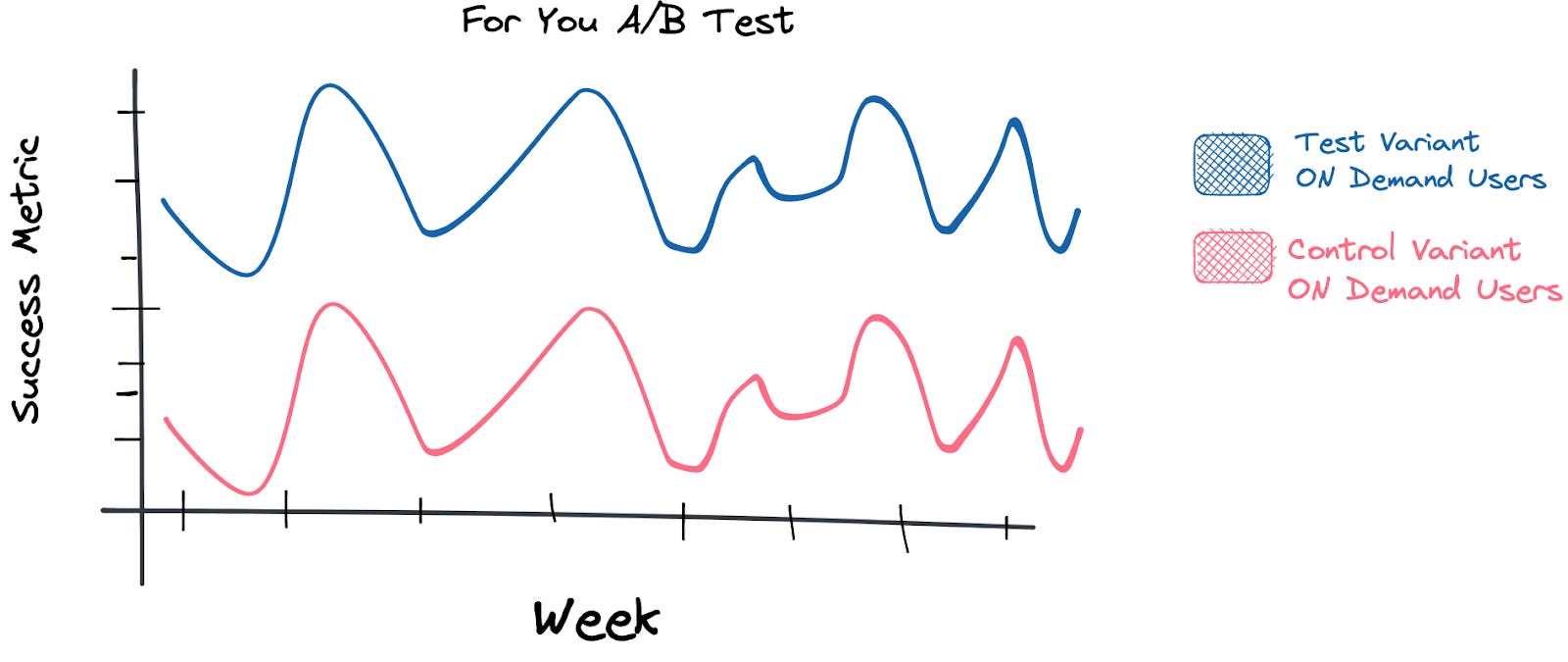
Then we clustered users by consumption patterns: users who prefer linear vs. users who prefer on-demand. We found that users who preferred linear content, also called live tv, never visited the For You homepage. And users who had an affinity for on- demand content that received the new personalized experience saw a considerable lift in the key success metric.
Next, we removed users who never visited the on-demand browse experience and recomputed the test results. What we found was more aligned with our initial predictions. For the users who watched more TV shows and movies on-demand, the success metric increased substantially when compared to users in the control who had similar viewing habits—more on how we split the segments to gather this insight in a future post.
A Lesson In Eligibility Criteria
What would we have done differently?
Well…clearly…we would have been far more thoughtful in defining the test and control segments. This is a great example of how the configuration of an experiment can directly influence the outcome.
The intent of the A/B test was never to activate users who had yet to watch on-demand content. If this was our goal, then including users who rarely use the feature would make sense. But instead, the goal was to measure the engagement for users who actually do use that particular part of the video product. Activating users is a far different problem space that would most likely be solved with a different solution.
Why does having tighter eligibility criteria that defines who is allocated to an experiment matter?
If you make a change that only impacts some users, the effect of the change that’s introduced to users in the test variant who fail to engage with the feature is zero. This has implications on the test analysis and caused what we observed in the initial results in which the impact of the For You homepage seemed little to none.
Another way to illustrate this is by using locality as an example.
Let’s say you’ve introduced a new feature that is only available in the United States. Your experiment is configured to include users from the United States, Germany, and France. However, keep in mind that this new feature is only available in the United States; therefore, Germany and France users will never be exposed to the feature, so the effect for them would be zero. Including users from Germany and France will introduce noise into the datasets that are used to compute the test results.
And Now…We Must Bid Adieu To The For You Test
For your results to be conclusive, there’s a lot of test details you need to get right. In the case of the For You experiment, we should have been more considerate with the segmentation criteria. The bar was too low – just MAUs whose account was “in good standing.”
I hope you enjoyed this quick story on why the eligibility criteria for allocating users to an experiment matters. This is just the tip of the iceberg; this particular experiment was a masterclass in what not to do (and what to do). As successful as the For You A/B test was, we got a lot wrong. Then again, we got a lot right too. The more mistakes we made, the more we learned about the experimentation methodology. There are certainly more examples that I will share in the future. However, we’ll pause the stories from this particular experiment for a few months to make room for other stories about holdbacks, clinical trials, croissants (life is an experiment, really), and so much more.
Until then, happy experimenting!